Toolkit: Научить команду корректно строить регрессии.
В свое время команда принесла мне для планового процесса файл расчетов прогнозных цен на продукты в зависимости от бенчмарка. По одной из линеек регрессия была построена по трем (да, именно трем) точкам. Я выдохнул и спросил, почему взяли только три точки. Ответ был тривиален, ну мы взяли данные за последние три года и просчитали. Мда-с.
Тут-то я и задал ключевой вопрос, а кто из вас имеет образование в виде матстата, регрессионного анализа, эконометрики или подобное. Оказалось, что в команде нет тех, кто в теме. К вопросу, о самых нужных предметах высшего образования. Порядок наводить надо, курс эконометрики за месяц не найдешь, поэтому возник вопрос, как научить команду корректно строить простые регрессии.
Ну, мы взяли статистику из опыта “сколько незнакомых слов в статье в зависимости от длительности изучения иностранного языка” и сделали спецтренинг, чтобы убить самые грубые ошибки регрессий. Далее со скриншотами. И суперкратким чеклистом и линком на файл в конце.
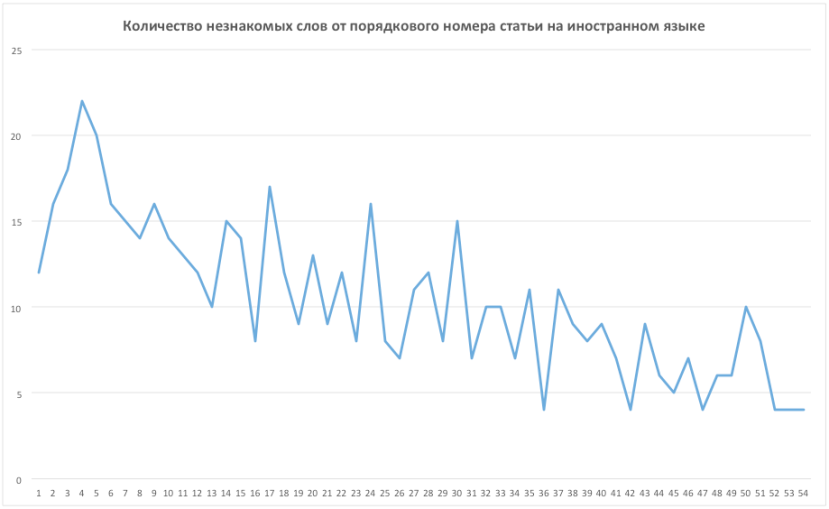
Первый шаг – это вообще взглянуть на данные в виде графика, прежде чем строить регрессию. По горизонтали дата, по вертикали количество незнакомых слов в статье на иностранном языке. Вывод простой – чем больше читаешь, тем меньше незнакомых слов в статье.

Второй шаг – включить в Excel пакет анализа и в нем регрессионный анализ. Из него построить табличку анализа качества регрессии. Это наш хлеб первого анализа. Вывод – с каждым днем количество незнакомых слов в статье падает на 0.11. Теперь по сути. Обычно, учат смотреть на R-квадрат, он здесь 65%, но не он главный. Первое, на что надо глядеть – это надежность всей регрессии (F-stat) и качество коэффициента (t-stat). Оба являются крайне малыми числами минус 13 порядка. Это означает, что регрессия и ее наклон надежны.

Третий шаг – попробуем улучшить регрессию одним из наиболее популярных способов, добавим еще одну переменную. Те, кто строят по R-квадрату тут и попадаются, потому что получают 65%. А вот t-stat нас спасает, показывая, что наклоны у регрессии совершенно ненадежные. То есть регрессия – мусор. Почему?
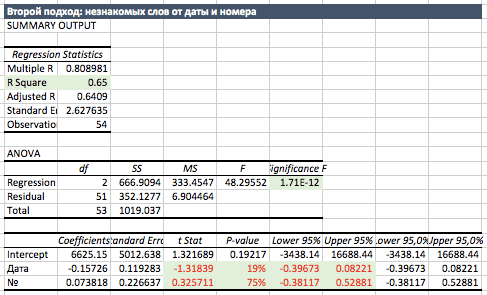
Четвертый шаг – проверим независимые переменные на корреляцию. Бинго. Эти обе переменные по сути являются взаимозаменяемыми. R-квадрат в 99% это показывает. Поэтому их использовать в анализе одновременно нельзя.

Пятый шаг. А если мы заменим одну независимую переменную (дату) на другую (номер), будет ли лучше? Строим и сравниваем с первым вариантом. Обе регрессии по показателям F-stat и t-stat одинакового качества. Потому что минус тринадцатая степень. Вывод получается, что либо с каждым днем на 0.11 незнакомых слов меньше, либо с каждой статьей на 0.22. Какую из регрессий выбрать, если они одного качества? Ту, которая логичнее. То, что знание иностранного языка улучшается с каждой статьей – это наша гипотеза.

Шестой шаг. Проверим, что глаза нас не подведут, и что от номера на взгляд напрашивается зависимость. Это действительно так.
Седьмой шаг. Поскольку мы будем экстраполировать, то очевидно, что через пару десятков мы упремся в ноль и придем к абсурду, что делать? Ведь отрицательных незнакомых слов быть не должно. Значит, регрессия не подходит для прогноза. Посмотрим, не меняется ли угол наклона регрессии. Поэтому построим по первым 27 точкам и по вторым 27 точкам.
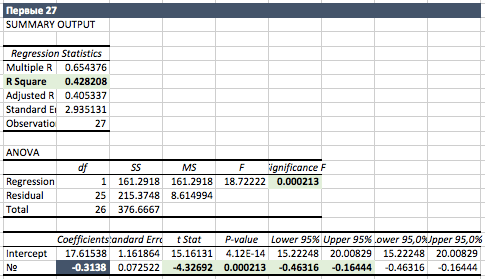
Видно, что по первым 27 точкам регрессия хуже, чем выше по 54. Но все равно надежная. Теперь смотрим по вторым 27.

И по вторым 27 тоже хуже. Но надежная. И видно, что угол наклона меняется от первых ко вторым. То есть скорость изучения языка падает. Сначала быстро, потом медленно.
Восьмой шаг. Раз наклон меняется, то нужно уходить в логарифмы. Посчитаем регрессию логарифма количества незнакомых слов от номера статьи. Получилась шикарная регрессия.

Девятый шаг. Надо проверить на глаз снова. Строим график. Теперь видно, что экстраполировать можно еще надолго вперед, а не только на пару недель, как в предыдущем графике.

Так в девять шагов мы построили регрессию, руководствуясь простым чек-листом. У тебя есть 20+ точек? Да, можно дальше. Нет – у тебя не хватает данных.
- График дает ощущение, что есть линейная регрессия? Да, делай дальше. Нет – дальше будут проблемы.
- Построй первую регрессию. Посмотри, чтобы значимости f-stat и t-stat имели почти нулевые показатели, то, что меньше 0.05 нас устроит. Иначе – скорее всего будет мусор.
- Попробуй добавить переменных. Если значимости t-stat развалились – значит добавил плохую независимую переменную. Она может быть связана с первой.
- Проверь переменные на взаимозависимость. Если они коррелируют, выбери лучшую.
- Посмотри качество регрессии от другой переменной. Где значимости f-stat и t-stat лучше? Одинаковы – выбери более логичную переменную.
- Опять построй график. Посмотри на него. Есть ли линейная регрессия? Да – продолжай, нет – подумай, прежде чем продолжать.
- Есть возможность экстраполировать? Да – делай. Из графика видно, что нет – давай разбираться с наклоном. Проверь наклон в начале отдельным анализом и наклон в конце другим анализом. Замедляется/ускоряется.
- Надо включать логарифмы. Включил логарифмы? Получилась хорошая регрессия? Отлично.
- Опять строим график и смотрим на него. Хороший? Тогда приехали. Плохой – либо отказывайся от гипотезы, либо ищи еще вводные.
Проинвестировав в команду всех стратмаркетологов, маркетологов, финансистов и стратегов двумя часами тренинга и одним мануалом, я думаю, что устранил порядка 95% кривых регрессий.
Кстати, если охота посмотреть файл, то он здесь.
Еще на эту тематику можно прочитать:
Как выучить иностранный язык за один год.
Поиск кадров или как мы отбирали студентов.
Моделирование как ответ на шесть жизненных вопросов
Формирование сценариев для стратегии и финмоделей.
На прошлой неделе опубликовали Как дискутировать с шефом или obligation to dissent.
Все остальные решения можно найти в Портфеле toolkits.
В планах дальнейших публикаций практик управления на уровне СЕО и СЕО-1:
— Работа с данными и регрессии.
— Активный совет директоров на практике.
— Первая цель управленческого учета в бизнесе.
